Da ich selbst in einige Fehler gelaufen bin, möchte ich hier eine Kurzdoku geben: Es reicht leider nicht aus einen mysqldump von MariaDB zu nehmen und dann in mysql zu importieren. Das Führt zu Fehlern.
Offenbar hat mysql ein Problem mit folgendem Part:
CREATE TABLE `document` (
`id` binary(16) NOT NULL,
`document_type_id` binary(16) NOT NULL,
`referenced_document_id` binary(16) DEFAULT NULL,
`file_type` varchar(255) NOT NULL,
`order_id` binary(16) NOT NULL,
`order_version_id` binary(16) NOT NULL,
`config` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`sent` tinyint(1) NOT NULL DEFAULT 0,
`static` tinyint(1) NOT NULL DEFAULT 0,
`deep_link_code` varchar(32) NOT NULL,
`document_media_file_id` binary(16) DEFAULT NULL,
`custom_fields` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`created_at` datetime(3) NOT NULL,
`updated_at` datetime(3) DEFAULT NULL,
`document_number` varchar(255) GENERATED ALWAYS AS (json_unquote(json_extract(`config`,'$.documentNumber'))) STORED,
Die Spalte „document_number“ wird mit json generiert. Das hat zu Fehlern geführt.
Der mit der Shopware-CLI erstellte mysql-dump war weitestgehend kompatibel. Ich musste lediglich ein Datumsfeld ändern, welches auf 0000-00-00 00:00:00 stand. Bisher sind keine Fehler aufgefallen. Ich hoffe das bleibt auch so!
Lustigerweise hat sich der create table Befehl von oben im neuen dump nicht geändert, wird aber jetzt von mysql akzeptiert. offenbar passiert vorher noch etwas magic was beim dump mit mysqldump nicht passiert.
Es gibt nichts wichtigeres als Backup Backup und hab ich schon gesagt: Backup? Gerade in Zeiten von Emotet und Co muss man extrem aufpassen. Ich möchte in diesem Beitrag meine Backupstrategie vorstellen.
Server – CC-BY-SA 3.0: https://commons.wikimedia.org/wiki/File:Wikimedia_Foundation_Servers-8055_35.jpg
Die Situation
Ich habe viele Server, darunter einige Nextclouds, Webserver und Mailserver. Auf den Servern ist notorisch wenig Platz, aber dafür ist auf dem TrueNAS genug Platz! Das TrueNAS ist nicht öffentlich im Netz, die Server allerdings schon, was diese natürlich zum idealen Angriffsziel machen. Alle Server basieren auf Linux bzw. BSD.
Die Backupstrategie
Ich habe meine Backupstrategie in mehrere Stufen eingeteilt.
Grundsätzliches
Pull nicht Push: Holt euch die Backups immer so, dass der Backupserver (der nur lokalen Zugriff zulässt) vom entfernten System abholt. Sollte der Server einmal übernommen werden, kann sonst der Angreifer auch den Backupserver übernehmen, bzw. weiß sofort von den Offsite-Backups.
Teste dein Backup: Teste auch ob das wiederherstellen deines Backups funktioniert. Am besten regelmäßig! Ein nicht getestetes Backup ist quasi kein Backup.
Stufe 1: Versionierung
Die erste Stufe schützt vor versehentlichem Löschen einer Datei. Speichert man die Änderungshistorie bzw. verschiedene Versionen können diese wiederhergestellt werden. Am einfachsten geht das bei ZFS (Dateisystem) mit regelmäßigen Snapshots bzw. bei der Nextcloud mit dem Addon „Versions“. Das geht natürlich nicht bei allen Servern z.B. dem Mailserver, aber hilft bei einfachen Fehlern enorm.
Stufe 2: Einfache Onsite Snapshots
Viele meiner Maschinen sind als VM abgebildet. Jeder Virtualisierungshost bietet die Funktion der Snapshots bzw. des Backups. Dabei wir dein Snapshot der gesamten VM angelegt. Dies hilft bei Fehlkonfigurationen oder dem versehentlichen Löschen größerer Dateien. Es kann auch helfen, wenn man sich einen Verschlüsselungstrojaner eingefangen hat, aber in der Regel wartet dieser sehr lange, um auch ältere Snapshots zu erwischen. Hier speichere ich meist 7 Tage.
Stufe 3: Offsite-Backup
Das Offsite-Backup möchte ich in diesem Beitrag näher erklären. Ich hole mir dabei aktiv die Daten der Server ab und speichere diese auf einem TrueNAS. Wie ich das genau umgesetzt habe ist weiter unten beschrieben.
Der Backupserver sollte sich natürlich auch in einem anderen Rechenzentrum, bzw. an einem anderen Standort befinden.
Stufe 3,5: Ein weiteres Offsite-Backup mit einer anderen Methoden
Das Offsite-Backup sollte auch mit einer anderen Methode auf den gleichen oder einen anderen Server kopiert werden. So kann man systematische Fehler im Backupsystem vermeiden. Holt man sich z.B. mit dem ersten Offsite-Backup die Snapshots der VM ab, sollte man mit einem zweiten Backup stupide die Daten mit rsync abholen. Dies hilft, sollte z.B. der Snapshot nicht reparabel defekt sein oder sollte die Backupmethode die Backups zerstört haben.
Stufe 4: Offline-Backup vom Backup
Im schlimmsten Szenario muss man davon ausgehen, dass auch der Backupserver von einem Angreifer übernommen worden ist. Ich hole mir dazu einmal die Woche die Backups auf eine externe Festplatte und ziehe diese danach vom Server wieder ab. Das hilft natürlich nicht, wenn der Angreifer längere Zeit auf dem Backupserver ist, aber zumindest eine weitere Hürde.
Traumhaft wäre natürlich ein offline-Backup mit mehreren Festplatten, die sich idealerweise dann auch noch nicht am gleichen Standort oder in einem Brandschutztresor befinden :).
Die Umsetzung der Stufe 3: Offsite-Backup mit TrueNAS
Stufe 1 und 2 müssen je nach System selbst umgesetzt werden. Stufe 3 kann relativ einfach mit TrueNAS eingerichtet werden. Auf die Idee hat mich wie bereits erwähnt Felix gebracht (vgl. https://flxn.de/posts/nextcloud-backup-to-freenas/ ) gebracht. In seinem Blog erklärt Felix bereits wie ein Backup mit TrueNAS bzw. FreeNAS umgesetzt werden kann. Ich habe die Idee lediglich insoweit modifiziert, dass die verschiedenen Versionen der Backups nicht auf dem Server selbst, sondern auf dem Backupserver erstellt bzw. gespeichert werden.
Im Folgenden bezeichne ich den TrueNAS-Server als „Backupserver“ und als Beispiel für das System, welche gebackupt werden soll „Webserver“.
Schritt 1: SSH-Verbindung mit Webserver aufbauen
Als Übertragungsweg wollen wir rsync über SSH verwenden. Dazu muss zunächst ein SSH-Schlüssel-Paar erstellt und auf den Servern verteilt werden. Nutzt am besten für jeden Server ein individuelles Schlüsselpaar. Wie das geht, ist im Internet 100x dokumentiert. Ein Beispiel: https://www.thomas-krenn.com/de/wiki/OpenSSH_Public_Key_Authentifizierung_unter_Ubuntu
Achtung: Bevor ihr weiter macht, solltet ihr euch per Konsole im TrueNAS mindesten einmal erfolgreich mit dem Webserver verbunden haben. Hinweis: Passwort-Geschützte SSH-Keys werden bei automatischen Backups nicht unterstützt.
Schritt 2: rsync-Backup-Jobs einrichten
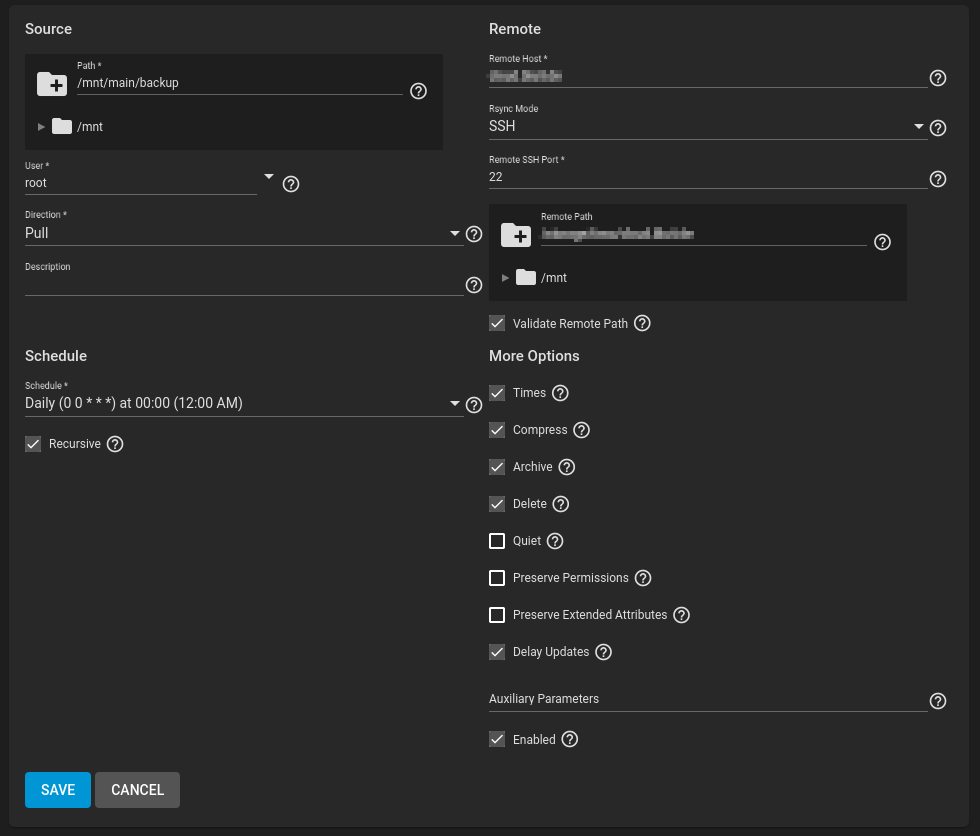
Hier können wir auf die komfortable Funktion von TrueNAS zurückgreifen. In der UI (TrueNAS) unter Tasks -> Rsync Tasks -> Add kann man einfach neue Jobs hinzufügen:
rsync-jobs mit TrueNAS
Die Wichtigsten Einstellungen dabei:
Source Path: Der Ordner auf dem Backupserver auf dem das Backup abgespeichert werden soll. Es ist sehr hilfreich, für die Backups ein eigenes ZFS-Dataset anzulegen. Warum zeigt sich später!
User: Der Benutzer auf dem Backupserver und Remote-Server (für SSH)
Schedule: Wie oft soll das Backup durchgeführt werden?
Remote Host: Der FQDN für den SSH-Zugriff auf den Webserver. Hier kann auch mit user@remotehost.de ein Benutzer angegeben werden.
Remote Path: Der Ordner auf dem Webserver, der gespeichert werden soll
Archive: aktivieren! Das ist wichtig um Berechtigungen und Benutzer zu erhalten
Delete: aktivieren! Das ist wichtig, damit auch gelöschte Daten synchronisiert werden
Den Rest kann man im default belassen. Es können nun viele verschiedene Backup-Jobs z.b. für verschiedene Verzeichnisse oder verschiedene Server angelegt werden. Wenn ihr in der Übersicht der rsync-Jobs einen einzelnen Job anklickt und „Run now“ klickt, kann der Job getestet werden. Je nach größe des Backups kann das natürlich etwas dauern.
Das tolle an rsync: Das erste Backup dauert lange, danach wird nur noch der DIFF gesichert und das Backup sollte deutlich schneller gehen!
Schritt 3: Snapshots der Backups
Nun kommt der Punkt an dem ich mich von Felix (vgl. https://flxn.de/posts/nextcloud-backup-to-freenas/ ) unterscheide: Nach einem erfolgreichen rsync-Job lege ich nun ein Snapshot des Backups an. Warum? So kann ich auf verschiedene Versionen des Backups zurück greifen und kann sogar fein-granular einzelne Dateien wiederherstellen. Das ist vor allem sinnvoll, wenn man identifizieren kann, ab wann ein System potentiell kompromittiert ist. Bzw. wenn man weiß, ab wann eine Datei fehlt oder defekt war.
Unter Tasks -> Periodic Snapshot Tasks kann in TrueNAS bequem ein regelmäßiger Snapshot eingerichtet werden. Ich habe täglich gewählt und speichere ein Jahr. Achtet darauf, dass der Snapshot-Zeitpunkt nicht zeitgleich zum Backup-Zeitpunkt stattfindet.
Jetzt zeigt sich auch, warum es hilfreich ist, für die Backups ein eigenes Dataset anzulegen: Die Snapshots können nämlich auf verschiedene Datasets angewendet werden. So könnt ihr verschiedene Zeitpunkte oder Speicherfristen für verschiedene Backups festlegen.
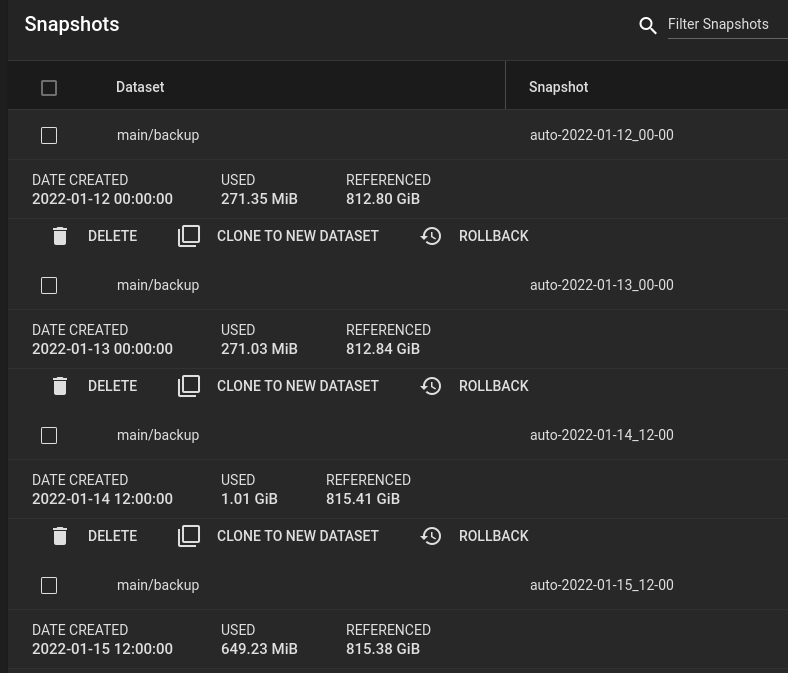
Die Snapshots des Backup
Sieht man sich nun die einzelnen Snapshots an, ist zu erkennen, dass ZFS sehr effizient ist und lediglich den DIFF speichert. So verbrauchen Snapshots nur sehr geringen Speicherplatz. Zum Wiederherstellen einzelner Versionen einfach auf „Clone to new Dataset“ klicken. Es wird dann ein neues Dataset angelegt auf dem die Daten durchsucht werden können.
Mal wieder ein kleiner Quickie: Meine Freundin hat Probleme mit den Händen und hat bei einer Kollegin DIE ergonomische Tastatur ausprobiert: Microsoft Natural Ergnomic Keyboard 4000. Leider wird diese nicht mehr verkauft und die Nachfolgermodelle sollen wohl nicht so dufte sein.
Die gebrauchte Microsoft Natural Ergonomic Keyboard 4000 Tastatur
Naja gut, dann einfach ebay Kleinanzeigen gesucht, gefunden und enttäuscht worden: Tastatur ist leider defekt angekommen. Die Tastatur wurde einfach nur als unbekanntes USB-Gerät erkannt -.-. Zuerst hatten wir die Treiber in verdacht und wollten schon aufgeben, da hat uns ein Freund den Tipp gegeben: Schaut euch mal das Kabel an.
Tada! Da ist der Fehler. Eine Kabelquetschung, fast unsichtbar und kaum zu spüren
Der Übeltäter im Kabel
Naja gut. Kabel tauschen.. hmm.. oder doch löten? Hab mich fürs löten entschieden. Die Tastatur war mit 24 Schrauben verschraubt ;).
Einzelkabel nicht vergessen zu isolieren
Noch nen Schrumpfschlauch drüber und zack fertig: Tastatur funktioniert wieder \o/
Ich habe schon länger mit ZFS (an der Oberfläche) zu tun, da ich Privat ein FreeNAS einsetze. Jetzt wollte ich ZFS mal auf Linux einsetzen und testen und was soll ich sagen: Ich bin begeistert!
Dieser Blogeintrag soll einen ersten Einstieg bieten und für mich als Dokumentation dienen ;).
Warum ZFS? Ich habe mir in der Hetzner-Serverbörse einen kleinen Storage-Server für eine Nextcloud geklickt:
2x SSD 512GB (Für Betriebssystem, Webserver und die Nextcloud-Daten)
2x HDD 3TB (Für die abgelegten Daten der Nextcloud)
Installation Grundsystem
Das Grundsystem ist ein Standard Ubuntu 20.04 LTS, welches auf den SSDs (in einer RAID0 Konfiguration) installiert wurde.
Installation und Konfiguration ZFS
Erst mal ZFS installieren:
apt install zfsutils-linux
Nun möchte ich die zwei HDDs (/dev/sda und /dev/sdb) als zfs-mirror installieren:
zpool create storage mirror /dev/sda /dev/sdb
Fertig :). Ab jetzt kann man den Mirror unter /storage/ verwenden.
Da ich den Server zusammen mit ein paar Freunden verwende, möchte ich jedem sein eigenes Dataset. Dataset ist der generische Begriff für ein ZFS-Dateisystem, Volume, Snapshots oder Klone. Jedes Dataset besitzt einen eindeutigen Namen in der Form poolname/path@snapshot. Die Wurzel des Pools ist technisch gesehen auch ein Dataset (Weitere Infos: https://www.freebsd.org/doc/de_DE.ISO8859-1/books/handbook/zfs-term.html)
zfs create storage/[name]
Anstelle von [name] einfach den jeweiligen Namen des Datasets angeben. Jetzt kann optional noch die Kompression aktiviert werden:
zfs set compression=lz4 storage/[name]
lz4 Compression kann ohne größere Geschwindigkeitsverluste für Lesen/Schreiben (bei modernen CPUs) eingesetzt werden. Die Anzeige der Compression-Ratio kann über folgenden Befehl erreicht werden:
Bei einem ZFS scrub werden die Festplatten auf Fehler geprüft und eventuelle defekte Dateien repariert. Man sollte den Scrub regelmäßig (etwa einmal im Monat durchführen). Dazu einfach einen einen Eintrag in die Crontab (crontab -e) schreiben:
da mein openVPN in letzter Zeit performance-Probleme zeigt, habe ich mich dazu entschlossen mir mal Wireguard anzusehen.
Ich persönlich benötige openVPN um all meine Server und Maschinen zu erreichen. Manche davon befinden sich hinter Firewalls oder NAT und openVPN hat da eigentlich schon die perfekte Lösung parat. Da aber jeder von Wireguard schwärmt, wollte ich mir das mal ansehen und was soll ich sagen? Es ist wirklich wirklich einfach!
Mehrere Clients (C01-C0*) mit variablen oder festen IP-Adressen sollen mit einem Server (S/C) kommunizieren, der eine feste IP-Adresse hat. Der Server ist Server als auch Client, aber dazu komme ich später.
Die Installation
Dieser Schritt ist auf allen Clients als auch Server identisch:
1
2
3
4
5
#Ubuntu
apt installwireguard
#Arch
pacman -S wireguard-tools
Das war auch schon die installation. Tatsächlich ist wireguard sehr schlank.
Die initiale Konfiguration
Jeder Client oder Server bei Wiregard bekommt einen Public und Private-Key. Das Key-Paar muss für alle Clients un Server erstellt werden. Dazu auf jedem System mit root in das Verzeichnis /etc/wireguard/ wechseln und folgenden Befehl ausführen:
1
umask077 $ wg genkey | teeprivate.key | wg pubkey > public.key
Eine genauere Eklärung zur Konfiguration folgt weiter unten. Auf dem Server muss zunächst das Interface für den Server definiert werden (der [Interface]-Part). Dort wird die private IP-Adresse des Servers, der Private-Key des Servers und weitere Einstellungen wie Port, etc. definiert.
Anschließend muss für jeden Client, der jeweilige Public-Key dem Server bekannt gemacht werden und die IP-Adresse des Clients definiert werden.
ACHTUNG: Der wireguard-Dienst darf bei einer Konfigurations-Änderung nicht laufen und sollte vorher mit systemctl gestoppt werden. Wenn ihr die Anleitung das erste mal durcharbeitet, ist der Server nocht nicht gestartet. Das gilt nur für jede Änderung die ihr nach dem Starten durchführt.
Erstellt die Datei /etc/wireguard/wg0.conf (root:root) mit folgenden Einträgen (natürlich eure einstellungen anpassen:
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Einstellungen für Server S/C
[Interface]
# Private IP-Adresse des Servers
Address = 10.10.0.1
SaveConfig = true
ListenPort = 41194
# Private-Key des Servers (statt ... den PrivateKey-Eintagen)
PrivateKey = ...
# IP-Forwarding innerhalb des VPNs
PostUp = sysctl net/ipv4/conf/%i/forwarding=1
# Einstellunge für Client C01
[Peer]
# Public-Key des Clients, statt ... den Public-Key des Clients eingeben
PublicKey = ...
AllowedIPs = 10.10.0.2/32
# Einstellungen für Client C02
[Peer]
# Public-Key des Clients, statt ... den Public-Key des Clients eingeben
PublicKey = ...
AllowedIPs = 10.10.0.3/32
# Einstellungen für Client C03
[Peer]
# Public-Key des Clients, statt ... den Public-Key des Clients eingeben
PublicKey = ...
AllowedIPs = 10.10.0.4/32
Für jeden weiteren Client muss lediglich ein weiterer [Peer]-Block mit den entsprechenden Keys/IPs definiert werden.
Hinweis: Das erstellte Interface wird den Namen der Konfigdatei haben. In unserem Fall also wg0.
Nun den Server starten:
1
2
systemctl enablewg-quick@wg0
systemctl start wg-quick@wg0.service
Die Client Konfiguration
Die Client-Konfiguration ist ähnlich zur Server-Konfiguration und sogar noch etwas einfacher.
Beim [Interface]-Part muss der Private-Key des Client eingetragen werden und die zu verwendende IP-Addresse.
Beim [Peer]-Part muss jetzt die Konfiguration de Servers angegeben werden. Also Endpoint (kann die feste öffentliche IP des Servers sein, egal ob ipv4 oder ipv6 oder eine Domain).
Auf allen Clients mit root die Datei /etc/wireguard/wg0.conf mit folgendem (ähnlichen) Inhalt anlegen:
01
02
03
04
05
06
07
08
09
10
11
12
13
# Einstellungen für Client C02
[Interface]
# Private-Key des Clients, statt ... den Private-Key des Clients eingeben
PrivateKey = ...
Address = 10.10.0.3/32
[Peer]
# Public-Key des Servers, statt ... den Public-Key des Servers eintargen
PublicKey = ...
AllowedIPs = 10.10.0.0/24
# Die feste IP bzw. Domain des wireguard-Servers
Endpoint = vpn.deinedomain.de:41194
PersistentKeepalive = 15
Auch hier wieder den Service starten:
1
2
systemctl enablewg-quick@wg0
systemctl start wg-quick@wg0.service
Fertig!
Test der Verbindung
Wenn keine Fehler fallen, solltet sich jetzt alle Server und Clients gegenseitig pingen können. Das Interface wird nach einem Neustart automatisch gestartet.
Erklärung der Konfiguration
Nun zur genaueren Erklärung der Konfiguration.
Der PostUP-Part beim Server
Dieser ist nötig, damit sich die Clients und Server gegenseitig sehen. Es handelt sich hierbei um das standard IP forwarding von Linux. In diesem Fall nur für das Interface „%i“ (%i wird automatisch durch den Interface-Namen ergänzt) in unserem Fall wg0.
AllowedIPs
Euch ist sicher aufgefallen, dass sich das Subnet für AllowedIPs beim Server und beim Client unterscheiden. Dies liegt darn, dass AllowedIPs beim Server und beim Client leicht unterschiedlich verwendet wird.
Auf dem Server verhält sich AllowedIPs wie ein Router und gibt an, wohin traffic geroutet werden soll. Es reicht daher /32 (also genau eine IP).
Auf dem Client verhält sich AllowedIPs wie eine access controll Liste. Wenn das Netzwerk dort nicht gelistet ist, wird der ankommende traffic einfach ignoriert. Daher haben wir hier /24 definiert. Es wird also alles von 10.10.0.* akzeptiert.
Heute ein kleiner Quicky. Ich fahre seit Neustem ein Dual-Boot (Arch Linux und Windows 10) auf meinem Laptop. Dadurch ergeben sich ungeahnte Problem:
Meine Bluetooth-Kopfhörer Bose Quiet Compfort 35 (QC35) müssen jedes mal neu gepaired werden. Dies liegt dran, dass beim Pairing-Prozess ein 128-Bit Key ausgehandelt wird, welcher zur Verschlüsselung der Bluetooth-Verbindung verwendet wird. Dieser wird natürlich nicht von den verschiedenen Betriebssystemen geteilt.
Wir müssen den Key also beiden Systemen bekannt machen.
Kopfhörer mit Linux pairen
Den Kopfhörer ganz normal mit Linux pairen, damit die Ordner-Struktur angelegt wird und wir später den Key austauschen können. Danach ins Windows booten.
Kopfhörer mit Windows pairen und Key herausfinden
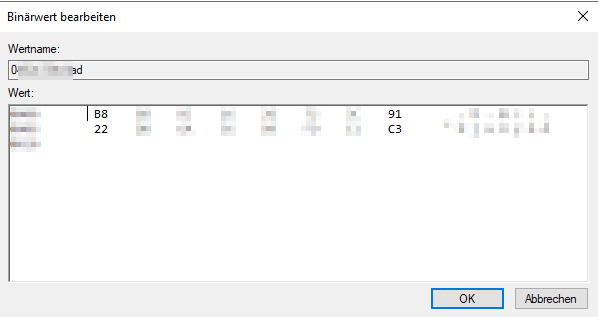
Nun einfach ein pairing der Kopfhörer durchführen. Anschließend findet man mit regedit einen Key unter:
Achtung bei Windows 10 20H2 sind die Keys nur vom System-Account auslesbar. Das heißt, es reicht nicht aus den Registierungs-Editor als Administrator zu öffnen. Es müssen auch Leserechte für Administratoren beim Key hinterlegt werden. Diese können nach dem Auslesen wieder entfernt werden.
Bluetooth-Key im Regedit
Um die richtige Device-ID herauszufinden kann man unter
sich die Namen ansehen und die richtige Device-ID herausfinden. Benötigt wird der 32-Stellige Code (im Bild beginnend mit B8 und endend auf C3; Ein fiktiver Beispielkey: 38B72423E8D2748DC6273744155EF614).
Key unter Arch Linux eintragen
Ich schreibe die Anleitung für Arch-Linux, aber das sollte auch auf anderen Distributionen funktionieren: Unter
die Datei „info“ bearbeiten. Hinweis: Die erste MAC-Adresse ist der Bluetooth-Controller im Laptop, die zweite MAC die vom Gerät. Wenn mehrere MAC-Adressen zu finden sind, sind in der datei „info“ weitere Informationen zum Gerät. So kann man das richtige herausfinden. Nun den Wert
[LinkKey]
Key=
gegen den Key von Windows austauschen (Ein fiktiver Beispielkey: 38B72423E8D2748DC6273744155EF614) .
Fertig! Nun noch einmal neustarten und anschließend sollten sich die Kopfhörer automatisch auf beiden Betriebssystemen connecten.
Mein neuer Laptop (Dell Latitude 5501) hat unter anderem ein LTE-Modem (Dell Wireless 5820e). Bei näherer Recherche stellt sich raus, es handelt sich um ein Intel XMM 7360 Modem. Leider wird dies allerdings nicht im Linux-Kernel supported, da Intel die Treiber ausschließlich für Windows 10 raus bringt: https://github.com/intel/linux-intel-lts/issues/7
Dieses Issue brachte aber auch die Lösung und diese möchte ich hier beschreiben.
Pakete nachinstallieren
Wir brauchen ein paar Pakte die wir nachinstallieren müssen:
Na da hab ich mir ja mal wieder was vorgenommen. Das neue Business-Notebook meines neuen Arbeitgeber ist eingetroffen. Leider komme ich bei meinem Arbeiten nicht um Windows 10 herum, aber ich kann es mir nicht nehmen lassen mir ein Linux auf der Kiste zu installieren.
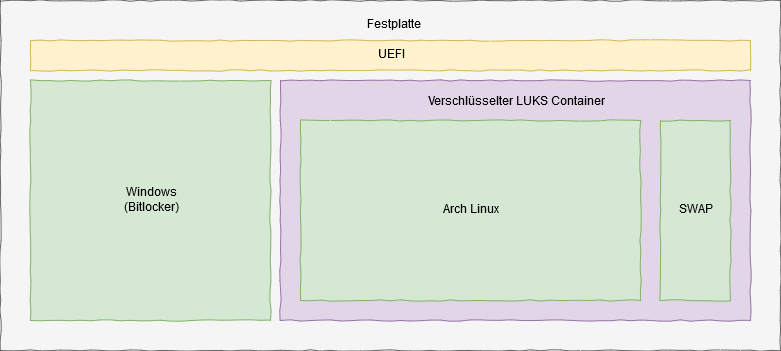
Aufgrund von Sicherheitsrichtlinien müssen beide Systeme verschlüsselt sein. Windows 10 mit Bitlocker (AES 256-bit) und Arch Linux mit einem AES 512-bit LUKS-Container.
Die Konfiguration
Das Windows 10 kommt mit einer 250 GB Partition bereits von meiner IT. Daher muss ich lediglich das Linux installieren ohne das Windows zu zerstören.
Die Konfiguration der Festplatte
Auf die Festplatte kommt (bzw. ist) eine UEFI Partition (Bootloader). Von dort kann man dann entweder ins Windows booten oder in einen verschlüsselten LUKS Container mit Arch Linux und einer kleinen SWAP-Partition.
Vorbereitung
Bitlocker deaktivieren
Zunächst muss Bitlocker deaktiviert werden. Leider habe ich keine Informationen, warum das so ist, nur „das Internet“ berichtet sonst von Problemen. Mit Admin-Rechten kann man das ganz einfach im Windows erledigen. Bitlocker kann danach wieder aktiviert werden.
SATA Operation auf AHCI stellen
Damit Linux die Platte erkennt und die Geschwindigkeit der SSD vollumfänglich ausgenutzt werden kann, muss im BIOS die SATA Operation auf AHCI gestellt werden. Unter Dell unter „System Configuration“ -> „SATA Operation“ -> „AHCI“
BIOS zunächst nicht umstellen und z.B. im „RAID on“ Modus belassen
Windows 10 starten
Eingabeaufforderung (cmd.exe) als Administrator öffnen
Abgesicherten Modus mit folgenden Befehl aktivieren: bcdedit /set {current} safeboot minimal
PC neustarten
Beim Neustart ins BIOS wechseln (Oft mit der Taste Entf oder F2)
Wechsel von IDE oder RAID on auf den AHCI Modus. Einstellung speichern
Windows 10 wird jetzt im abgesicherten Modus gestartet
Eingabeaufforderung (cmd.exe) als Administrator öffnen
Abgesicherten Modus mit folgenden Befehl beenden: bcdedit /deletevalue {current} safeboot
PC neustarten
Der AHCI Modus ist jetzt aktiviert
Hinweis für Thunderbolt Docking Stationen
Mein Dell Latitude 5501 hat eine WD19TB Dockingstation welche mit Thunderbolt angeschlossen wird. Diese wurde nach der Umstellung auf AHCI nicht mehr erkannt. Die Lösung: Im BIOS muss das Security Level auf „none“ gestellt werden.
Eine Installation von Arch Linux mit USB-Stick mit Secureboot ist zwar möglich. Es wird aber nicht empfohlen (vgl. https://wiki.archlinux.de/title/UEFI_Installation). Es können wohl auch weitere Probleme auftreten.
Installations-Medium erstellen
Und natürlich müssen wir auch noch Linux irgendwie installieren können. Daher brauchen wir einen leeren USB Stick und ein Arch-Image. Image herunterladen und dann mit DD auf einen leeren USB-Stick schreiben:
Eine Linux-root-Konsole sollte am Bildschirm erscheinen. Im Grunde ist alles im sehr ausführlichen Arch Wiki beschrieben. Leider sind die einzelnen Artikel aber teilweise leicht versteckt und es gibt Diskrepanzen zwischen den Übersetzungen. Einige Punkte sind nur im deutschen Wiki beschrieben, Anderes nur im englischen Wiki. Ich halte mich gerne an den Beginners guide: https://wiki.archlinux.org/index.php/Installation_guide
Ab jetzt folgt eine Kurzzusammenfassung. Im Beginners Guide ist alles ausführlicher Beschrieben.
Deutsches Tastaturlayout laden:
1
loadkeys de-latin1
Freien Speicherplatz partitionieren
Zunächst kann mit dem Befehl
1
fdisk -l
eine Übersicht geschaffen werden. Wie Windows die Partitionen angelegt hat. Bei mir ist eine 1TB NVME Festplatte verbaut bei der Windows drei Partitionen angelegt hat:
/dev/nvme0n1p1: EFI System – Die Partiton für den UEFI Bootloader
/dev/nvme0n1p2: Microsoft reserved – Reservierter Speicher für Sicherungsdaten von Microsoft
/dev/nvme0n1p3: Microsoft basic data – Die C-Partition für Windows 10
Damit sind 250GB belegt und es bleiben noch 750GB für Linux. Mit
1
gdisk /dev/nvme0n1
können die weiteren Partitionen angelegt werden. Die Wichtigsten Befehle:
p # Print der aktuellen Tabelleo # Neue Tabelle anlegenn # Neue Partition erstellenw # Schreibe Tabelle auf die Festplatte
Da wir nur eine Partition für den LUKS-Container brauchen (siehe Bild oben) reicht es, wenn wir eine neue Partition über die restlichen 750GB des Speichers erstellen:
n [Enter]
Partition number (default 4): [Enter]
First sector: [Enter]
Last sector: [Enter]
Hex code or GUID: 8E00 (Für Linux LVM) [Enter]
p (Um nochmal alles anzuzeigen)
w (schreiben der Tabelle auf die Festplatte)
Mit „p“ kann man sich jetzt nochmal die gesamte Tabelle anzeigen lassen. Eine vierte Partition für Linux LVM sollte angelegt worden sein. Mit „w“ kann die Tabelle auf die Festplatte geschrieben werden.
Die soeben angelegte Partition unter /dev/nvme0n1p4 wird nun verschlüsselt. Dazu können verschiedene Algorithmen und Schlüssellängen gewählt werden. Welche Algorithmen auf dem System am schnellsten funktionieren, kann mit einem Benchmark ermittelt werden:
1
cryptsetup benchmark
In meinem Fall fällt die Auswahl auf aes-xts-plain64 mit 512-bit Schlüssellänge:
Nun einfach der Anweisung auf dem Bildschirm folgen. Bitte sicherstellen, dass auch die richtige Partition ausgewählt wird, da LUKS alles verschlüsselt. Anschließend muss der Container wieder geöffnet werden und auf LVM gemapped werden.
1
2
# Öffnet verschlüsselten Cotainer wieder und mapped auf "lvm"
cryptsetup open --type luks /dev/nvme0n1p4 lvm
Mit dem Befehl „lsblk“ kann man Prüfen ob alles geklappt hat.
LVM innerhalb des LUKS-Containers erstellen
Wir haben zwar jetzt einen (offenen) verschlüsselten Container, haben darin aber noch kein LVM. Dieses wird mit den folgenden Befehlen erstellt:
1
2
3
vgcreate main /dev/mapper/lvm # Erstelle Volume Group auf /dev/mapper/lvm mit Namen "main"
lvcreate -L 32G main -n swap # Erstelle 32GB SWAP
lvcreate -l 100%FREE main -n root # Erstelle root mit Rest
Achtet bitte beim letzten Befehl darauf: Ein kleines „-l“ kein „-L“. Zum Swap: Ich halte mich nach wie vor daran: 2x RAM-Größe = SWAP-Größe. Mit dem Befehl „lsblk“ kann man wieder Prüfen ob alles geklappt hat.
Filesystem erstellen
Jetzt fehlt nur noch das Filesystem auf den innerhalb des Containers erstellten Partitionen:
1
2
mkfs.ext4 /dev/mapper/main-root
mkswap /dev/mapper/main-swap
Festplatten mounten
Nun müssen lediglich die Partitionen an der richtigen Stelle gemounted werden und die Installation kann beginnen:
Anschließend die Datei /boot/loader/entries/arch-uefi.conf mit folgendem Inhalt erstellen:
title Arch Linux
linux /vmlinuz-linux
initrd /initramfs-linux.img
options cryptdevice=/dev/nvme0n1p4:main root=/dev/mapper/main-root lang=de locale=de_DE.UTF-8
Außerdem noch den Fallback anlegen: /boot/loader/entries/arch-uefi-fallback.conf
title Arch Linux Fallback
linux /vmlinuz-linux
initrd /initramfs-linux-fallback.img
options cryptdevice=/dev/nvme0n1p4:main root=/dev/mapper/main-root lang=de locale=de_DE.UTF-8
Nun noch die Datei /boot/loader/loader.conf bearbeiten und folgende Einträge anpassen/ergänzen:
default arch-uefi
timeout 3
Damit wird lediglich festgelegt, welches der Default ist und wie viele Sekunden (timeout) gewartet wird.
Das wars! Jetzt kann Linux gestartet werden.
Bitlocker wieder aktivieren
Bitlocker kann nun im Windows wieder aktiviert werden. Achtung: Es kann vorkommen, dass Bitlocker eine neue Partition anlegt. Dadurch verschiebt sich der LUKS Container (z.B. von nvme0n1p4 auf nvme0n1p5 und Linux könnte nicht mehr starten wollen mit dem Fehler „Not a valid LUKS container“. Dazu muss dann die Konfiguration /boot/loader/entries/arch-uefi.conf bzw. /boot/loader/entries/arch-uefi-fallback.conf nochmal angepasst werden.
Zwar kann ich mich (noch) nicht mit dem Gedanken der Hausautomatisierung anfreunden, dennoch habe ich schon länger mit dem Gedanken gespielt meine Wohnung mit Sensoren auszustatten. Ich wollte die Zimmer meiner Wohnung möglichst kostengünstig mit praktischen Sensoren ausstatten.
Disclaimer: Ich arbeite hier teilweise mit Geräten die in 220V eingesteckt werden. Wenn ihr nicht wisst was ihr tut: Finger weg! Und sowieso niemals nachmachen!
Die Hardware
Was braucht man alles? Sensoren, Broker, Datenbankserver und Stromversorgung. Alles am besten aus einer Hand. Natürlich gibt es sowas, aber doch ziemlich teuer. Hier die Hardware die ich verwendet habe:
Plattform
Ideal wäre ein Grundsystem mit WLAN, Platz für Sensoren, einer stabilen Stromversorgung und idealerweise noch ein schönes Gehäuse dazu. Zum Glück gibt es so etwas Ähnliches schon:
Sonoff Socket S20
Die S20 gibt es für ~10 Euro bei Aliexpress und bieten fast alles was wir brauchen. Darin enthalten ist ein ESP der für WLAN sorgt und die Zwischensteckdose ist sogar schaltbar. Dieses Feature ignoriere ich aber zunächst, da ich derzeit noch keinen Sinn darin sehe, meine Wohnung zu automatisieren. Die S20 sind robust verbaut und wenn man diese aufschraubt, kann man man 4 Pins erreichen, an die Sensoren angeschlossen werden können: Fast perfekt
Leider ist das Gehäuse vollständig geschlossen, weswegen ich die 4 Pins für die Sensoren nach außen gelegt habe.
Sensoren
Bei der Wahl der Sensoren habe ich mich aufgrund der limitierten Pin-Anzahl für I²C Sensoren entschieden. Diese können parallel zueinander an die 4 Pins gehängt werden. Mögliche Sensoren (eine Auswahl):
BMP280
Luftdruck
Temperatur
Luftfeuchtigkeit
~2-3 Euro
BH1750
Helligkeit
~1-2 Euro
CCS811
Luftqualität
~10 Euro
BME680
Luftdruck
Temperatur
Luftfeuchtigkeit
Luftqualität
~15 Euro
Ich hab mich zunächst mal nur für BMP280 (sehr günstig und sehr praktisch) und den BH1750 (kostet fast nix, ich weiß noch nicht was ich mit den Werten anfange) entschieden.
Die Luftqualitätssensoren habe ich bestellt und ein Test steht noch aus. Allerdings bin ich noch nicht ganz überzeugt. Ich hätte gerne einen C0x Sensor aber sowas ist einfach super teuer.
Hardware zusammenbauen
Im Grunde muss für die Vorbereitung der Hardware einige Kabel angelötet werden, die Sensoren aufgesteckt werden und eine neue Firmware konfiguriert werden.
S20 vorbereiten und neue Firmware flashen
Der Sonoff S20 kann über das Lösen von drei Schrauben geöffnet werden. Anschließend kann man auf der Platine vier Anschlussmöglichkeiten. Da es absolut nicht zu empfehlen ist, bei geöffnetem Gehäuse die S20 mit Strom zu versorgen. Die Anschlüsse können über vier Kabel und einem kleinen Loch nach draußen geführt werden.
Die Platine eines Sonoff S20 mit aufgelöteten Kabeln
Verbesserungsidee für die Profis: Vierpolige Klinkenstecker bzw. -buchsen eigenen sich hervorragend um die Anschlüsse sauber nach draußen zu führen.
Das Pinout ist in folgendem Bild zu erkennen:
Pinout Sonoff S20
Firmware konfigurieren
Als Firmware verwende ich ESPEasy (Github, Hauptseite). Dazu benötigt man zunächst die Software aus dem neusten Release von Github: https://github.com/letscontrolit/ESPEasy/releases und den dazu passenden Flasher für ESPs. Da die Anleitung etwas ausführlicher ist und ich dieses noch an einem Beispiel nachvollziehen muss, würde ich zunächst hierauf verzichten und dies noch nachreichen. Wenn ihr es trotzdem vermisst, einfach einen Kommentar schreiben.
Sensorpaket löten
Die angesprochenen I2C Sensoren können parallel angebracht werden und benötigen neben der Stromversorgung nur zwei Leitungen. Zu beachten ist dabei nur:
Sonoff S20
Sensor
GND
GND
VCC
VIN/VCC
RX
SDA
TX
SCL
Zwei Sensoren gestapelt
Sonoff S20 konfigurieren
Die neue Firmware stellt ein Webinterface zur Verfügung. Die IP-Adresse wird dabei beim Flashen angezeigt. Solltet ihr verpasst haben, die IP-Adresse zu notieren, könnt ihr in eurem Router nochmal nachsehen oder die IP-Adresse per nmap herausfinden.
Auf die Beschreibung der üblichen Konfigurationen wie WIFI, NTP und Co verzichte ich an dieser Stelle. Hier kann man sich gut durchklicken und die Infos sollten klar sein.
Controller konfigurieren
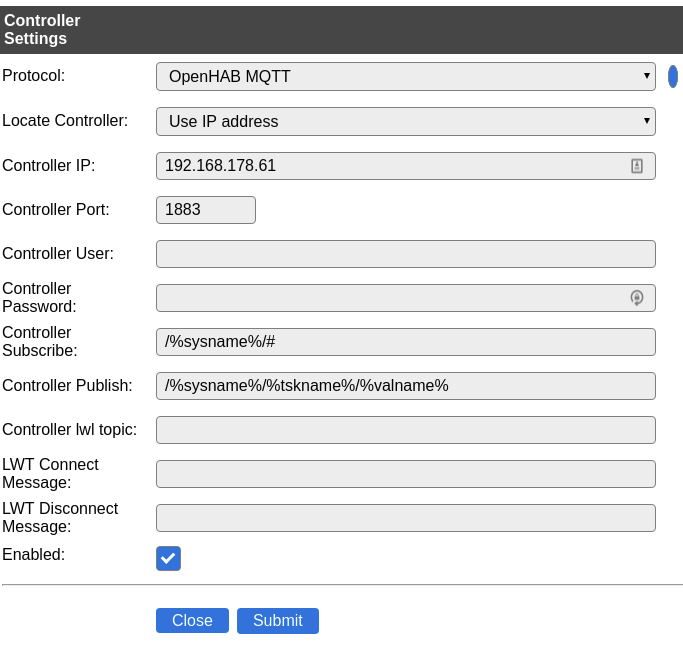
Für den Controller verwenden wir ein Raspi. Wie dieser konfiguriert wird, ist weiter unten zu sehen. Leider beißt sich hier die Katze in den Schwanz, denn für die Konfiguration benötigt man die IP-Adresse des Controllers. Bitte zunächst also den Raspi fertig einrichten und hier wieder weitermachen. Der Controller ist dazu da, die Daten, die am ESP Easy erfasst werden, weiterzuverarbeiten und zu speichern. Eine Beispielkonfiguration für den Raspi sieht wie folgt aus:
Controller-Konfigratuion für den Raspi
I2C Sensoren aktivieren
Um Pins für die Sensoren frei zu kriegen, muss zunächst der serielle Port abgeschaltet werden. Unter Tools -> Advanced -> Enable Serial Port deaktivieren. Anschließend den Controller neustarten. Danach unter Hardware -> I2C Interface die korrekten Pins einstellen:
Pinbelegung für die Sonoff S20
Wenn die Sensoren angeschlossen sind können diese über Tools -> I2C Scan getestet werden. Die Ausgabe sollte dabei wie folgt aussehen:
I2C Scan bei ESP Easy
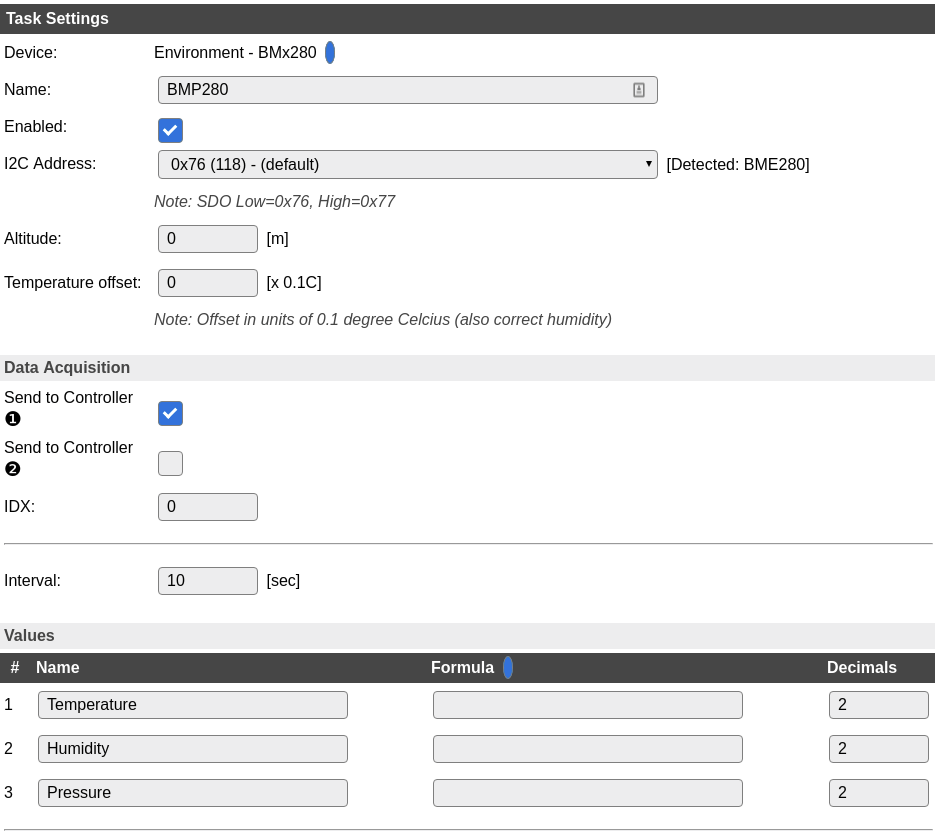
Im obigen Beispiel werden zwei Sensoren erkannt und gleich die vermuteten Sensoren angezeigt. In diesem Fall: BH1750 und BMP280. Die Sensoren können nun über Devices konfiguriert werden. Hier ein Beispiel für den BMP280. Zu beachten ist, dass „Send to Controller“ nicht aktiv ist, solange kein Controller konfiguriert ist. Ein Controller muss zunächst installiert werden.
Als Server fungiert ein einfacher Raspberry Pi 3 (35 €). Hier funktioniert aber alles auf dem man folgende Tools installieren kann:
InfluxDB
Grafana (optional)
Telegraf
Mosquitto
Ein allgemeiner Hinweis: Ich gehe in diesem Beitrag aus gründen der Komplexität nicht auf die Sicherheit eurere Systeme ein. Bitte informiert euch selbst, wie ihr
Rasbian installieren
Als Betriebssystem für den Rapsi verwende ich Rasbian. Dazu gibt es offizielle Anleitungen, wie dieses installiert werden kann. In dieser Anleitung verzichte ich darauf.
Mosquitto installieren
Mosquitto ist ein einfacher MQTT message broker. Die Installation und das starten ist dabei relativ einfach:
Mosquitto kann über das File /etc/mosquitto/mosquitto.conf konfiguriert werden. Wenn man keine Authentifizierung möchte, reicht die standard-config aus.
InfluxDB installieren
Als Datenbank-Backend verwenden wir InfluxDB. influx ist eine Zeitreihendatenbank und eignet sich besonders gut für die Art der erfassten Daten. Dazu zunächst die Datei /etc/apt/sources.list.d/influxdb.list mit folgendem Inhalt erstellen:
deb https://repos.influxdata.com/debian stretch stable
Achtung: Hier wird eine Paketquelle aus einer potentiell nicht vertrauenswürdigen Quelle verwendet. Dies ist immer mit Vorsicht zu genießen. Da dies aber die Paketquelle von Influx selbst ist, ist diese relativ vertrauenswürdig.
Nun werden wir root, installieren den RSA-Key von influx und installieren die Datenbank:
sudo su curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
apt update apt install influxdb
Telegraf installieren und konfigurieren
Um die mqtt-Daten zu erfassen, kann Telegraf verwendet werden. Nebenbei erhält man dann auch noch Daten der Auslastung des Raspi. Das Paket telegraf kommt aus den selben Quellen wie die influx-Datenbank.
apt install telegraf
Nach der Installation muss die Config-Datei unter /etc/telegraf/telegraf.conf angepasst werden. Die Meisten Punkte müssen lediglich auskommentiert werden. Wenn keine weiteren Änderungen nötig sind, kann der unten stehende Config-Teil auch einfach ans Ende der Datei kopiert werden.
# Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
## MQTT broker URLs to be used. The format should be scheme://host:port,
## schema can be tcp, ssl, or ws.
servers = ["tcp://localhost:1883"]
## Topics to subscribe to
topics = ["#",]
## Pin mqtt_consumer to specific data format
data_format = "value"
data_type = "float" ist
Anschließend müssen noch beide Services enabled und gestartet werden.
Grundsätzlich reicht dieses Setup schon aus. Auch können ab jetzt schon die Daten in der InfluxDB gefunden werden. Allerdings wollen wir die Daten auch visuell besser aufbereiten.
Grafana Installieren
Grafana eignet sich hervorragend für die Darstellung der von uns erfassten Daten. Leider ist die Version des grafana im rapsi-repo sehr alt, daher nehmen wir auch hier eine andere Version. Weitere Informationen zur Installation der Paketquellen zu grafana sind hier zu finden: http://docs.grafana.org/installation/debian/ Erstellt dazu /etc/apt/sources.list.d/grafana.list mit folgendem Inhalt:
deb https://packages.grafana.com/oss/deb stable main
Achtung: Hier wird eine Paketquelle aus einer potentiell nicht vertrauenswürdigen Quelle verwendet. Dies ist immer mit Vorsicht zu genießen. Dies ist allerdings der von Grafana selbst gewählte Weg. Nun muss noch der GPG-Key für das Grafana-Paket installiert werden:
Ab jetzt kann man unter der IP-Adresse des Raspis und dem Port :3000 Grafana erreichen:
http://192.168.123.123:3000
Für die weitere Konfiguration einfach dem Webinterface folgen und z.B. einen Benutzer einrichten bzw. Passwörter ändern. Der Standard-Benutzer ist admin mit dem Passwort admin.
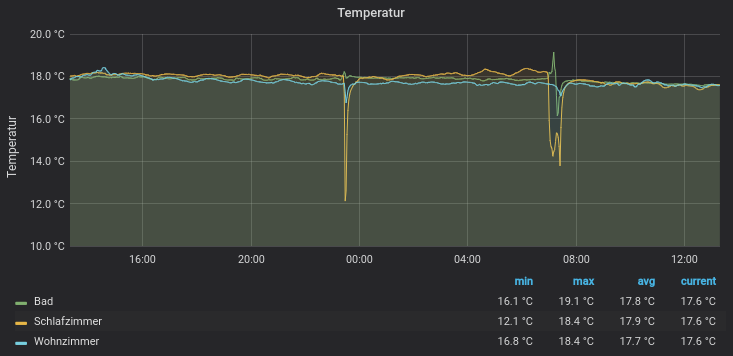
Beispiel für Darstellung erfasster Daten
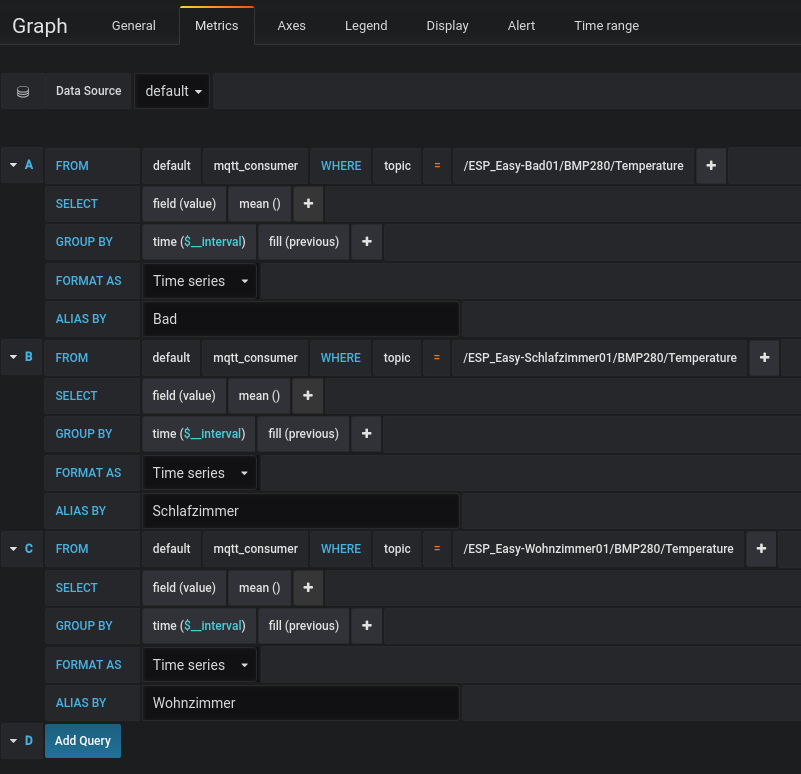
Ab hier sind euch alle Freiheiten gegeben, die erfassten Daten grafisch aufzubereiten. Als Beispiel die Erfassung der Raumtemperatur mit drei Sensoren. Dazu einfach ein „Panel“ hinzufügen und folgende Daten erfassen:
Beispiel für die grafische Aufbereitung der erfassten Daten mit Grafana
Anschließend können noch die Achsen und die Legende bearbeitet werden. Hier empfiehlt es sich die verschiedenen Einstellmöglichkeiten einfach durchzubprobieren. Man hat hier sehr viele Einstellmöglichkeiten. Anschließend sollten die Daten aufbereitet werden und als Grafik dargestellt werden:
Gimiks
Da wir nun Telegraf für die Datenerfassung nutzen, können wir auch die Daten des Rapsi auswerten. Telegraf erfasst alle Daten des Raspi automatisch. Also Load, Temperatur, CPU Auslastung etc. Natürlich ist das nicht nötig, aber wenn wir die Daten schon erfassen, können wir diese doch auch gleich mit Grafana auswerten. Eien tolle Funktion in Grafana: Man kann sich fertige Dashboards hinzufügen. Unter https://grafana.com/dashboards findet man verschiedene fertige Dahsboards mit einer dazugehörigen ID. Beispiele für Telegraf sind z.B. das Dashboard mit der ID 61 oder 928. Dazu einfach seitlich auf das „+“ -> Import Dashboard und anschließend die gewünschte ID eingeben. Im folgenden Dialog muss noch die Datenquelle (InfluxDB) angepasst werden auf telegraf.
Beispiel-Dashboard für Telegraf (928)
Updates
[04.02.2019] Update der Paketquellen und Gimiks
Grafana hat nun endlich selbst eine Paketquelle für das aktuelle Grafana. Dies wurde in der Anleitung ergänzt.
Es gibt jetzt auch die Anleitung wie ich die Prozessdaten des Raspi erfassen kann.
[11.02.2019] Mosquitto ergänzt
Ich habe doch tatsächlich den Teil über Mosquitto vergessen. ist jetzt ergänzt.
Threema ist schon ein sehr toller Messenger, aber leider gibt es in Sachen Backup noch viel zu tun. Ein Schritt in die richtige Richtung ist der Threema Safe. Damit lassen sich grundlegende Einstellungen sichern. Unter anderem:
Threema-ID
Profildaten
Kontakte
Einstellungen
Was allerdings nicht gespeichert wird:
Chatverläufe
Mediendaten
Threema bietet für Threema Safe verschiedene Optionen. So kann man die Daten in der Cloud von Threema speichern, oder in einem eigenen Webdav-Verzeichnis. Da viele die Threema nutzen ausreichend paranoid sind um fremden Cloud-Speichern nicht zu verwenden und auch eine eigene Nextcloud betreiben ist die zweite Option das Mittel der Wahl.
Threema Safe in der eigenen Nextcloud
Die Nextcloud bietet alles, was Threema Safe benötigt. Eine Anleitung wie man dies einrichtet ist im Folgenden zu finden.
Serviceaccount Anlegen
Zunächst einmal sollte ein Service-Account für Threema angelegt werden. Die Threema-App benötigt Login-Daten für das Speichern des Backups. Hierfür sollte man wenn möglich nicht die Daten seinen Haupt-Accounts verwenden.
Neuen Account anlegen: Als Administrator einfach oben rechts auf den Benutzer klicken -> Benutzer -> Neuer Benutzer
Hier einfach einen Benutzernamen (z.B. „threema“ mit einem sicheren Passwort erzeugen. Passwort und Benutzername werden später benötigt.
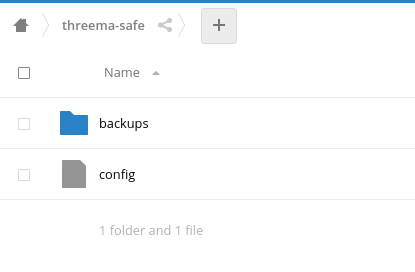
Ordner-Sturktur anlegen
Threema verlangt eine spezielle Ordner-Sturktur auf dem Server. Legt einen beliebigen Ordner für die Backups an (möglichst ohne Leerzeichen). Innerhalb dieses Ordners MUSS ein Ordner namens „backups“ vorhanden sein. Außerdem muss eine Datei namens „config“ angelegt werden, mit folgendem bzw. ähnlichem Inhalt:
1
2
3
4
{
"maxBackupBytes": 52428800,
"retentionDays": 180
}
maxBackupBytes legt dabei die maximale Backup-Größe fest, retentionDays wie lange dieses Backup aufgehoben werden soll. Die Ordnerstruktur sollte danach etwa so aussehen:
Threema Safe Ordnerstruktur in der Nextcloud (Web-Ansicht)
Threema Safe Konfiguration in der App einstellen
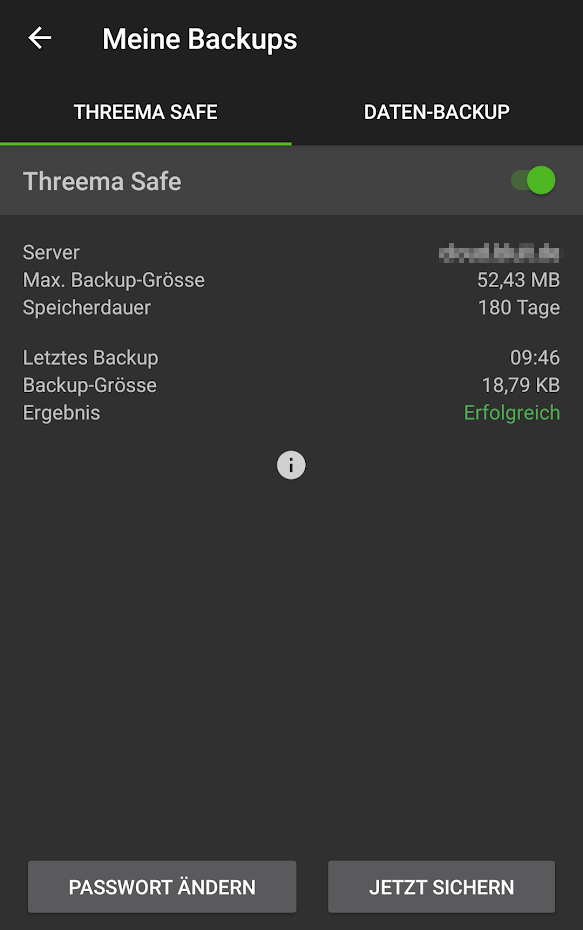
Das schlimmste ist erledigt. Nun nur noch die Einstellungen in die Threema-App übernehmen:
Username und Passwort wie von euch im ersten Schritt gewählt. Werden die Einstellungen gespeichert fragt Threema noch nach einem Passwort mit dem das Backup auf dem Server verschlüsselt werden soll.
Nun sollte in der Threema-App folgende Ansicht sichtbar sein:
Threema Safe Einstellungen auf dem Handy mit der Nextcloud
Abschließende Hinweise
Threema speichert ab jetzt selbstständig die oben genannten Daten etwa alle 24 Stunden. Aber vorsicht: Dies ist kein vollständiges Backup!
Nach wie vor werden keine Gesprächsverläufe bzw. Mediendateien gesichert. Diese müssen weiterhin über „Meine Backups -> Daten-Backup“ erstellt und vom Handy gesichert werden. Hier muss Threema definitiv noch nacharbeiten.